
A study by consultancy Legal Nodes, which included MikeOSS, shows that no matter how good a general model appears to be, it’s the legal AI ‘scaffold’ that really makes a difference when it comes to performance.
Legal AI expert Nestor Dubnevych told Artificial Lawyer that the study looked at Claude Opus 4.8 and then tested it on legal tasks using different set-ups (see below) and see AL interview (also below).
He found that: ‘The same model performed differently across different scaffolds. This means that model-only evaluation gives an incomplete picture of legal AI performance.
‘In legal work, the quality of the output depends not only on the base model, but also on the scaffold around it: context, workflow logic, prompt improvement with available skills, planning, agentic loops, retrieval, tool calling.’

AL Interview with Nestor Dubnevych at Legal Nodes
Please tell the readers who you are and what you do.
Legal Nodes is a tech-enabled legal consultancy. After we started using AI in legal work, we realised that to understand its capabilities properly, we needed to learn how to evaluate it.
That is how we started LN Labs. It’s our research arm focused on benchmarking AI models and legal AI systems against real-world legal tasks that our legal experts deal with every day.
Why did you decide to run these evaluations?
Recently, LAB and RedlineBench were released by Harvey and Crosby. They also published leaderboards where models barely passed a score of 10 out of 100.
With those evaluations, it was not clear how much AI performance depended on the model’s own capabilities versus scaffold engineering.
OpenAI has recently mentioned that domain-specific scaffolding allows teams to pull out the model’s full capabilities.
So the question for us was: if domain-specific scaffolding impacts model capabilities, why is almost nobody benchmarking legal scaffolds (or wrappers) around the models?
Why did you pick these systems?
We wanted to test the hypothesis that a properly engineered legal scaffold can materially affect AI performance.
So we took one model (Claude Opus 4.8) and evaluated it across three different publicly available environments:
- Claude Chat
- Cowork with Legal Plugin
- MikeOSS
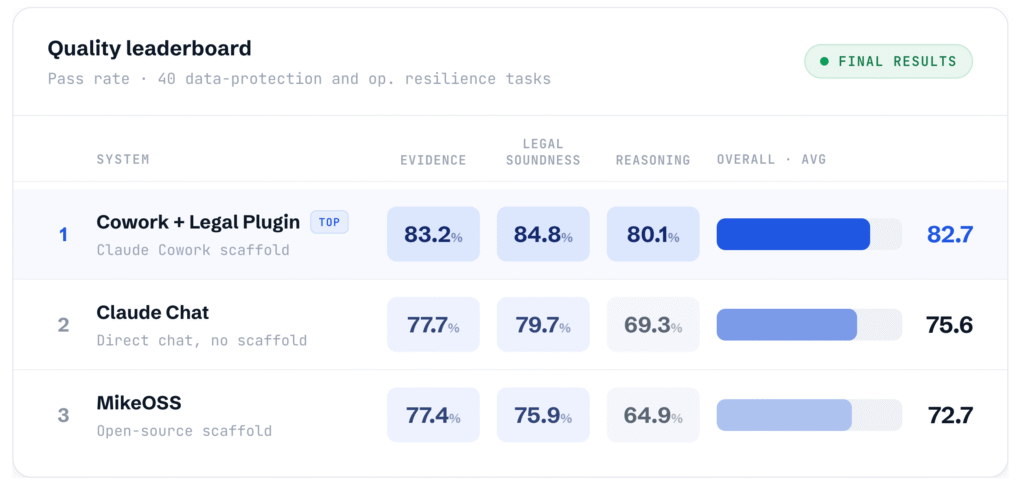
We built a small eval dataset of 40 tasks in data protection and digital operational resilience, then ran the same model across these different scaffolds.
What are your main conclusions?
These are still early results, but they confirmed our core thesis: the same model performed differently across different scaffolds.
This means that model-only evaluation gives an incomplete picture of legal AI performance.
In legal work, the quality of the output depends not only on the base model, but also on the scaffold around it: context, workflow logic, prompt improvement with available skills, planning, agentic loops, retrieval, tool calling.
What does this tell us about the future of legal AI?
After recent news about model training from Harvey and Kirkland & Ellis, we expect the industry to focus heavily on post-training and fine-tuning.
That is important. But our evaluation shows that legal AI teams should not overlook scaffold engineering and the structuring of company context layers.
For many legal teams this may be the fastest way to improve performance before fine-tuning starts delivering sector-wide results.
–
And also:
Will Chen, creator of MikeOSS, comment to AL following the results:
I welcome the benchmark and I believe it is a good first step towards having impartial third party benchmarking of legal AI harnesses.
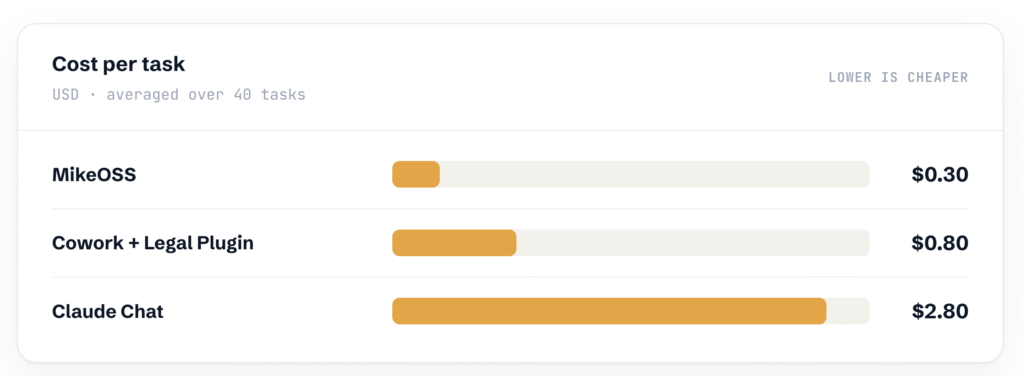
I think the results show that Mike is able to perform satisfactorily and achieve performance standards that while are slightly lower than Claude and Cowork, show significant cost savings of around 60% and 90% per task relative to Cowork and Claude despite using the same model. This shows that it’s a great option for enterprise teams especially in environment of rapidly rising token costs.
I also note that most of my focus on Mike thus far has been getting it to work well on transactional tasks like contract review. But going forward I will examine how Mike can be improved for the privacy and compliance advisory related tasks that the LegalNodes benchmark focussed on. I suspect that a good deal of improvement can be made just by adding some related skills to Mike.
—
AL Comment:
What this study shows is that the legal tech market’s renewed focus on building out specially customised ‘scaffolds’ for legal work makes total sense. The idea that general models alone are good enough really seems to be struggling now.
It also suggests that moves to train open source models will indeed provide better combined results, (although the above Claude models in this case are not open source LLMs).
The cost point is also important. MikeOSS came out cheaper by a long way. And token costs are increasingly going to weigh on the legal market’s choice of tools.
Perhaps the next study to do is to test post-trained open source models vs general models vs general models and legal scaffolds – and perhaps a combination of all of these in different configurations. AL’s guess is that a top general model + curated data-heavy scaffolds + post-training open source model(s) combined all in one system would give the best results. But….let’s see. What do you think?
P.S. it’s also one of the first studies AL has seen that includes the Claude Legal Plugins. And on this, albeit small, study the Plugin has come out quite well.
P.P.S. Also note, today’s study by LegalOn – see AL article earlier.
—
More about the study here.
—
(Conference advert)
Come and join us in New York and London this November at Legal Innovators!
Legal Innovators New York – Nov 17 and 18.


Legal Innovators UK – London, Nov 4 and 5
Discover more from Artificial Lawyer
Subscribe to get the latest posts sent to your email.